Scanpy 是一个基于 Python 分析单细胞数据的软件包,内容包括预处理,可视化,聚类,拟时序分析和差异表达分析等
数据:Anndata
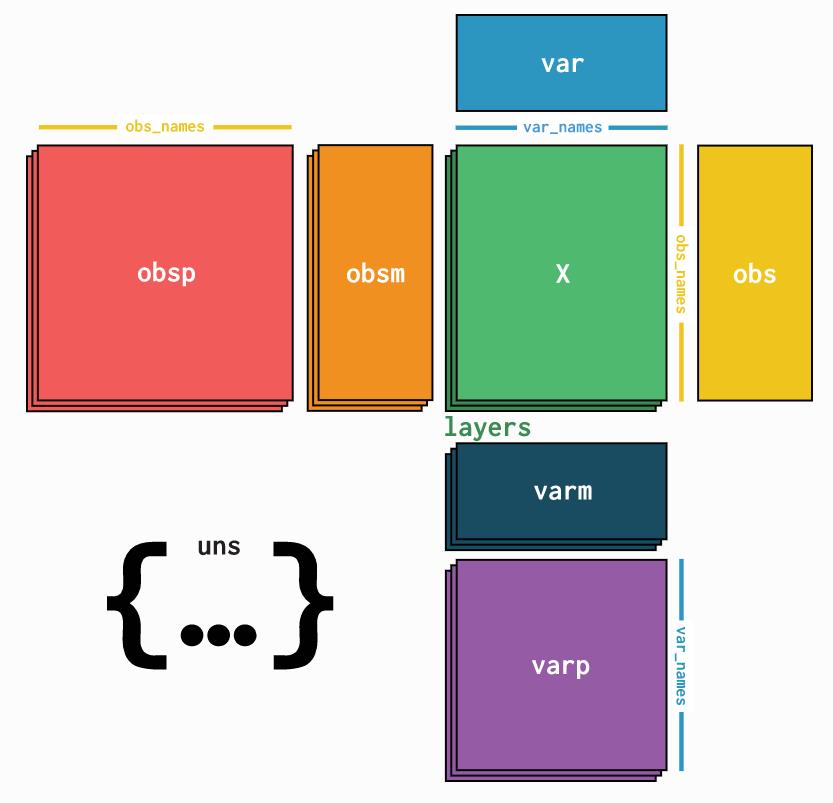
anndata - Annotated data — anndata
| 信息 | 数据类型 | |
|---|---|---|
| X | 矩阵信息 | ndarray |
| obs | 观测值 | pandas Dataframe |
| var | 特征值 | pandas Dataframe |
| uns | 非结构化数据 | dict |
| obsm | 观测的多维注释 | ndarray |
| obsp | 观测的配对注释 | ndarray |
| varm | 特征的多维注释 | ndarray |
| varp | 特征的配对注释 | ndarray |
文件格式
fragments 文件
peak_counts 文件:h5ad
组件
1.pp:数据预处理
2.tl:额外添加信息
3.pl:可视化
数据预处理
1.sc.pp.filter_cells
sc.pp.filter_cells(data, min_genes=None, max_genes=None)
细胞筛选,保留测序的基因数为[min_genes,max_genes]的细胞 (注意,min和max不能同时传递),运行过后obs多个一个属性 n_genes
2.sc.pp.filter_genes
sc.pp.filter_genes(data, min_cells=None, max_genes=None)
基因筛选,保留在细胞出现次数为[min_cells,max_cells]的基因 (注意,min和max不能同时传递),运行过后var多个一个属性n_cells
3.sc.pp.highly_variable_genes
sc.pp.highly_variable_genes(data,
n_top_genes=None,
min_disp=0.5
max_disp=inf,
min_mean=0.0125,
max_mean=3)
4.sc.pp.normalize_total
sc.pp.normalize_total(adata, target_sum=None, inplace=True)
归一化扩展,对每个细胞进行标准化,以便每个细胞在标准化后沿着基因方向求和具有相同的总数target_sum
可视化
1.sc.pl.highest_expr_genes
sc.pl.highest_expr_genes(adata, n_top=20)
可视化所有细胞中计数最多的20个基因,同时计算百分比含量